ELM Architecture
The goal of the ELM architecture is to provide a platform that can execute real-time compute intensive tasks within a very limited power budget. It must be utilizable by the software that runs on it and able to be implemented by the underlying circuits.
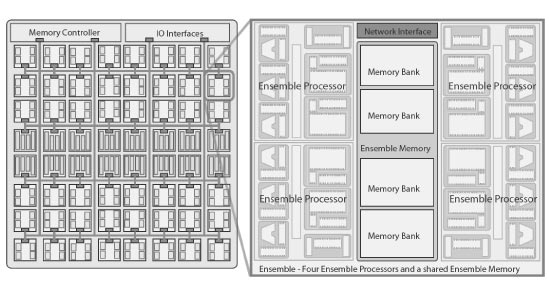
The ELM System [taken from CAL, 1/08]
System Level
The ELM system is comprised of many simple tiles, called Ensembles, that contain software managed memory (EM) and several Ensemble Processors (EPs). These small tiles are much more energy efficient than large cores and offer more computation contexts for a given die area. The tiled architecture relies on software (under development) to take advantage of the available computation resources with the philosophy that a larger software up front cost will be amortized over a programs' lifetimes. The interconnection network provides mechanisms for streaming data from Ensemble to Ensemble, matching the streaming programming model.
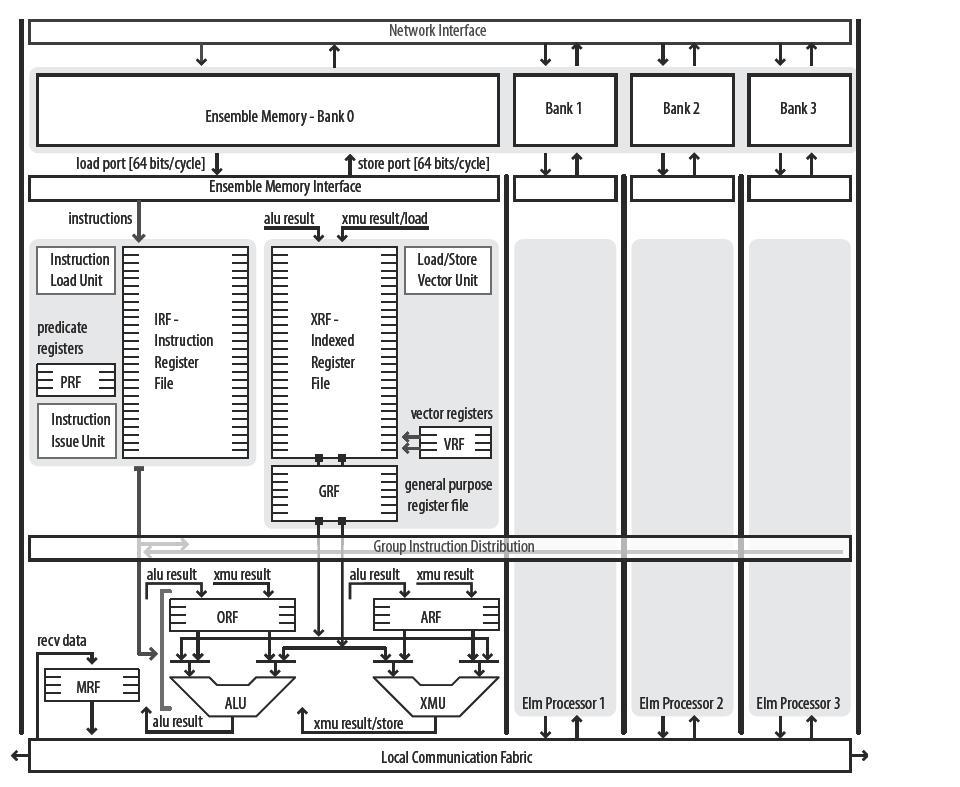
An ELM Tile
Ensemble - Performance
Using a two wide instruction, each EP can issue both an arithmetic and memory operation. Memory operations can be used to set up data streams into local register files before the operands are needed by the ALU, hiding load latency. These stream operations not only apply to data, but also instructions. Blocks of code can be pre-fetched into the instruction registers (IRFs) prior to execution in order to eliminate stalling on jumps. Since the memory is software controlled, real-time programmers do not experience variable length memory accesses typical of caches. Also included is a vector register file (VRF) that is accessed via an auto-updated counter. This mechanism allows loops to operate on data without the need to issue instructions updating a memory pointer. The vector registers counters are configurable, allowing for programmers to use different stride lengths, starting, and stopping points.
The ELM architecture supports single-instruction multiple data (SIMD) execution within an Ensemble. When in SIMD mode, all EPs execute in lock-step with instructions coming from a single IRF. Any IRF in Ensemble can be the issuer of instructions, effectively quadrupling the amount of instructions that can be stored.
Ensemble - Power
EPs execute instruction from a 64-entry, software managed instruction register file. This tag-free SRAM can be accessed much cheaper than L1 caches often found in other processors. Since the ELM architecture is targeting embedded applications, the small size of the register files is adequate to hold the inner loops of programs and does not cause significant, if any, performance degradation. ELM's SIMD mode also reduces the instruction-supply energy by having only one instruction fetch per cycle in each Ensemble.
The ELM data-supply is built around a hierarchy of register files, all of which are explicitly managed by software. All of the Ensemble Processors (EPs) in a tile access the software-managed, banked Ensemble Memory (EM). The software managed EM eliminates the cost of tag checks, which can account for a majority of access energy. The EP itself contains several SRAM sources of data operations. Each of these SRAMs vary in size and location in the datapath. For example, the Operand Register File (ORF) is accessed in the execute stage and only contains enough memory for four operands. This small structure uses less energy to access than the general register file (GRF) and does not have to pass through retime registers.