ELM Compiler
The ELM compiler takes C code written for one core (called Ensemble Processor, EP, in ELM) and converts it to assembly code. It must interface with the high-level programming tools, providing feedback about feasibility constraints for a given partitioning scheme. The compiler not only makes performance based optimizations, but also energy-based ones. When targeting only one EP, the compiler supports standard C. When tareting multiple EPs and ensembles, primitives that are not expressible in C, such as operations for static/dynamic networks and distributed memory allocation, are used by intrinsic function calls that are generated by the high-level programming system.
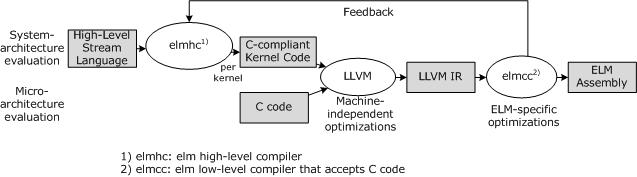
Figure 1: Global Structure of the ELM Compiler
Figure 1 shows our compiler system. The output of the high level tool-chain (or standard C code) acts as the input to the the LLVM compiler front-end. The LLVM Intermediate Representation (IR) is then optimized specifically for ELM. Two main optimization areas are discussed below. Finally, the compiler outputs ELM assembly, and also feed information back to the high-level system and programmer about the achievability of real-time constraints. This iterative process is used to find an fast, low-energy partitioning of a program.
Data Supply
In the ELM architecture, the register hierarchy is software-managed. This creates a challenge when attempting to do register allocation and instruction scheduling independently. For example, if allocation occurs first, the minimum latency between instructions changes depending on where in the register hierarchy intermediate values are allocated. We use two approaches to address this phase ordering problem: 1) interleaving allocation and scheduling and 2) unified allocation and scheduling
Instruction Supply
Since Compiler-Managed Instruction Stores (CMISs) are tagless, they are more area-efficient and consume less energy per each access. An advantage of CMISs is that the compiler has full control of locating each instruction in CMISs, allowing for a minimization of misses on code. However, the instructions stored do not reflect dynamic information, which can lead to redundant loading of instructions. In typical embedded applications, however, loops tend to be small and very predictable, often fitting into the CMISs and allowing the uncommon branch to be expanded which cleanup and reload code. The figure below shows that CMISs actually achieve lower or similar miss rate than that of caches with the same capacity in embedded applications. The figure below compares L1 access count of various L0 instruction stores: LC denotes loop cache, FA denotes fully-associative cache, DM denotes direct-mapped cache, CMIS denotes CMIS without profiling information, and CMIS_P denotes CMIS with profiling information provided to the compiler. The L1 access count is normalized to the case where there is no L0 instruction store (i.e., every instruction access goes to L1). We evaluated 17 MiBench applications.
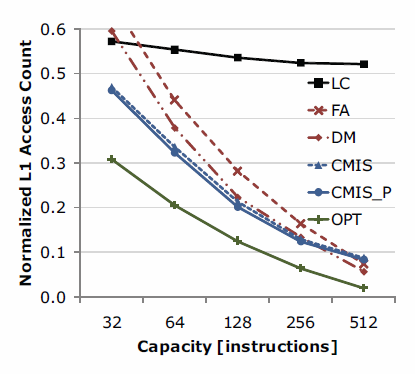
L1 access count of various L0 instruction stores [taken from TechReport, 09]
The figure below shows that CMISs achieve on average 84\% reduction of instruction supply energy.
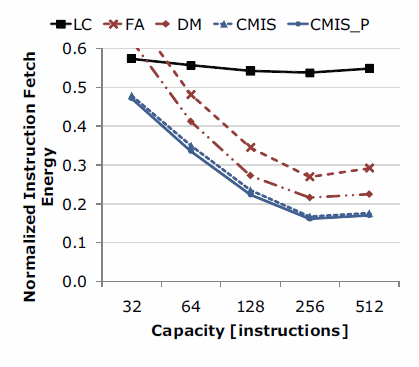
Energy consumption of various L0 instruction stores [taken from TechReport, 09]