ELM Programming
The programming toolchain of ELM is responsible for taking user code, partitioning it, scheduling data transfers, and outputting C code for each Ensemble Processor (EP). The high-level language called Elk (an old version is described in [1]) utilizes a stream programming model. In this model, the application is described with a collection of actors (or filters) connected by data streams (Figure 1). The high-level partitioner modifies the application to meet real-time constraints with high processor utilization; actors in the bottleneck are parallelized while actors underutilizing processors are merged. The low-level compiler takes each partition and generates executables for the ELM micro-architecture.
Compared to StreamIt, Elk has the following advantages. First, Elk supports multiple stream inputs and outputs so that we can avoid contrived stream interleavings resulted from single input and single output constraint. Second, the computation model of Elk is not limited to synchronous data flow. SDF is a great model if the properties of filter execution can be statically determined. However, Elk and backend computation model do not assume the SDF model so that we can support wider range of embedded applications. This is more important when we target applications such as 3D rendering that traditionally have not been categorized as embedded applications but soon will be incorporated in many embedded devices. Third, the optimization objective of Elk is not limited to minimizing the execution time. For embedded systems, minimizing the energy consumption subject to real-time constraints is the common optimization objective. Rather than finding as much as parallelism, our programming system judiciously applies parallelization on bottleneck actors and avoids excessive communication and synchronization overhead from over-parallelization. Fourth, Elk supports constructs for exploiting locality. Last and probably the most important difference is that Elk and programming system will be evaluated in the ELM architecture which is designed for streaming programming model (but note that our programming system can target other architectures and ELM is also not limited to streaming programming model). Our programming system back-end will generate code in a natural way for streaming applications instead of adding workarounds to support architectures that not designed for streaming programming model.
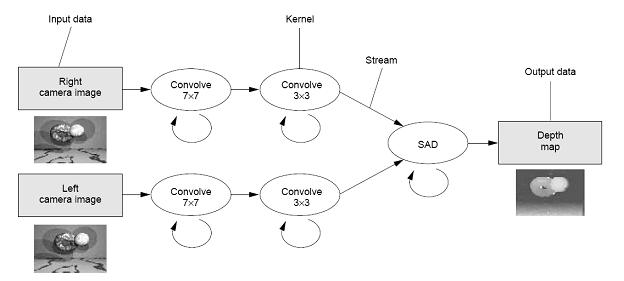
Figure 1. Stream Programming Model [2]
For more details about Elk programming language, see here.
The compiler page describes the low-level compiler.
[1] David Black-Schaffer, "Block Parallel Programming for Real-time Applications on Multi-core Processors", Stanford PhD Thesis, 2008
[2] B. Khailany., W. J. Dally, U. J. Kapasi, P. Mattson, J. Namkoong, J. D. Owens, B. Towles, A. Chang, and S. Rixner,"Imagine: Media Processing with Stream." IEEE Micro, 2001