The Imagine kernel compiler and cycle accurate simulator were used to generate the following performance results for four applications and three representative media processing kernels. Table 1 contains the results of these applications.
Arithmetic Bandwidth Application Performance Applications Stereo Depth Extraction 11.92 GOPS (16-bit) 320x240 8-bit gray scale at 198 fps MPEG-2 Encoding 15.35 GOPS (16- and 8-bit) 320x288 24-bit color at 287 fps QR Decomposition 10.46 GFLOPS 192x96 matrix decomposition in 1.44 ms Polygon Rendering 5.91 GOPS (floating-point and integer) 35.6 fps for 720x720 "ADVS" benchmark Polygon Rendering with Real-Time Shading Language 4.64 GOPS (floating-point and integer) 16.3M pixels/second; 11.1M vertices/second Kernels Discrete Cosine Transform 22.6 GOPS (16-bit) 34.8 ns per 8x8 block (16-bit) 7x7 Convolution 25.6 GOPS (16-bit) 1.5 us per row of 320 16-bit pixels FFT 6.9 GFLOPS 7.4 us per 1,024-point floating-point complex FFT Table 1: Application and Kernel performance.
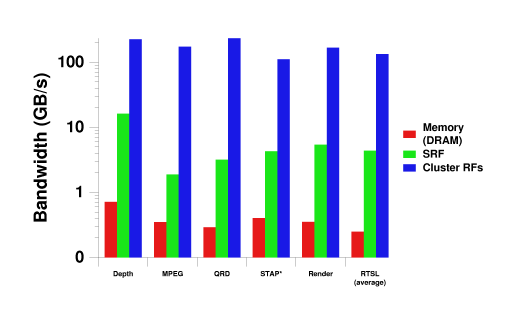
Figure 1. Measured application bandwidth for each level of the bandwidth hierarchy.
Figure 1 shows the sustained bandwidth used by these applications and demonstrates the effectiveness of the 3-level bandwidth hierarchy. Each level of the hierarchy sustains an order of magnitude more bandwidth than the previous level. The kernels sustain a high computation rate and require hundreds of gigabytes per second of local register bandwidth. The SRF, which provides higher bandwidth than a general-purpose global register file, cannot even provide half of the data bandwidth used by the arithmetic units. Therefore, without the small, fast local register files at the bottom of the bandwidth hierarchy, Imagine would not be able to achieve such high sustained performance on media kernels.
Imagine's stream architecture allows it to achieve high sustained performance for these media processing kernels. For the FFT kernel, for instance, an average of over 21 arithmetic operations are issued on every cycle for a sustained performance of 6.9 GFLOPS. The inherent parallelism in media applications and the Imagine bandwidth hierarchy results in similar sustainable performance on a variety of media processing applications.