Overview
Imagine is a programmable single-chip processor that supports the stream programming model. The figure to the right shows a block diagram of the Imagine stream processor. The Imagine architecture supports 48 ALUs organized as 8 SIMD clusters. Each cluster contains 6 ALUs, several local register files, and executes completely static VLIW instructions. The stream register file (SRF) is the nexus for data transfers on the processor. The memory system, arithmetic clusters, host interface, microcontroller, and network interface all interact by transferring streams to and from the SRF.
Imagine is a coprocessor that is programmed at two levels: the kernel-level and the stream-level. Kernel functions are coded using KernelC, whose syntax is based on the C language. Kernels may access local variables, read input streams, and write output streams, but may not make arbitrary memory references. Kernels are compiled into microcode programs that sequence the units within the arithmetic clusters to carry out the kernel function on successive stream elements. Kernel programs are loaded into the microcontroller's control store by loading streams from the SRF. At the application level, Imagine is programmed in StreamC. StreamC provides basic functions for manipulating streams and for passing streams between kernel functions. See the Imagine Stream Programming page for more information on the stream programming model.
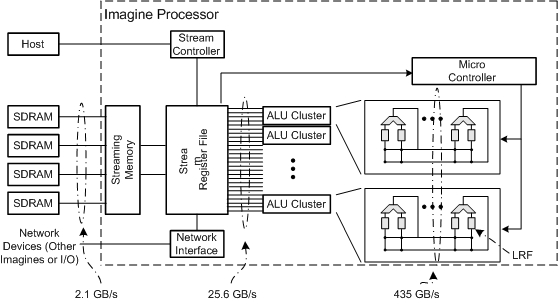 One of the key architectural innovations of the Imagine architecture
is the three tiered storage bandwidth hierarchy. The bandwidth
hierarchy enables the architecture to provide the instruction and
data bandwidth necessary to efficiently operate 48 ALUs in parallel.
The hierarchy consists of a streaming memory system (2.1GB/s), a
128KB stream register file (25.6GB/s), and direct forwarding of
results among arithmetic units via local register files
(435GB/s). Using this hierarchy to exploit the parallelism and
locality of streaming media applications, Imagine is able to sustain
performance of up to 18.3GOPS on key applications. This performance
is comparable to special purpose processors; yet Imagine is still
easily programmable for a wide range of applications. Imagine is
designed to fit on a 2.56cm^2 0.18um CMOS chip and to operate at
400MHz.
One of the key architectural innovations of the Imagine architecture
is the three tiered storage bandwidth hierarchy. The bandwidth
hierarchy enables the architecture to provide the instruction and
data bandwidth necessary to efficiently operate 48 ALUs in parallel.
The hierarchy consists of a streaming memory system (2.1GB/s), a
128KB stream register file (25.6GB/s), and direct forwarding of
results among arithmetic units via local register files
(435GB/s). Using this hierarchy to exploit the parallelism and
locality of streaming media applications, Imagine is able to sustain
performance of up to 18.3GOPS on key applications. This performance
is comparable to special purpose processors; yet Imagine is still
easily programmable for a wide range of applications. Imagine is
designed to fit on a 2.56cm^2 0.18um CMOS chip and to operate at
400MHz.
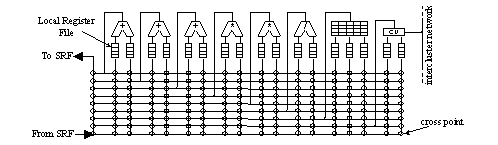 Eight arithmetic clusters, controlled by a single microcontroller,
perform kernel computations on streams of data. Each cluster
operates on one record of a stream so that eight records are
processed simultaneously. As shown in the figure to the right, each
cluster includes three adders, two multipliers, one divide/square
root unit, one 128-entry scratch-pad register file, and one
intercluster communication unit. This mix of arithmetic units is
well suited to our experimental kernels. However, the architectural
concept is compatible with other mixes and types of arithmetic units
within the clusters.
Eight arithmetic clusters, controlled by a single microcontroller,
perform kernel computations on streams of data. Each cluster
operates on one record of a stream so that eight records are
processed simultaneously. As shown in the figure to the right, each
cluster includes three adders, two multipliers, one divide/square
root unit, one 128-entry scratch-pad register file, and one
intercluster communication unit. This mix of arithmetic units is
well suited to our experimental kernels. However, the architectural
concept is compatible with other mixes and types of arithmetic units
within the clusters.